ArtDL - a multi label classification task example
Package import and variables definition
from odin.classes import TaskType, Metrics, Curves, CustomMetric, DatasetClassification, AnalyzerClassification
# define the path of the GT .json file
dataset_gt_param = "../../test-data/classification-ml/gt_art.json"
# define the path of the folder that contains the predictions .txt files for each model
path_to_detections = "../../test-data/classification-ml/predictions"
# define the task type
classification_type = TaskType.CLASSIFICATION_MULTI_LABEL
# define groups of categories which are similar to each other (useful for the error analysis)
similar_classes=[[1, 4, 7], [2, 6, 10], [5, 8], [3, 6, 9]]
# define the file_name for the meta-annotations
properties_file = "properties_art.json"
Dataset
my_dataset = DatasetClassification(dataset_gt_param,
classification_type,
proposals_paths=path_to_detections,
similar_classes=similar_classes,
properties_file=properties_file,
save_graphs_as_png=False)
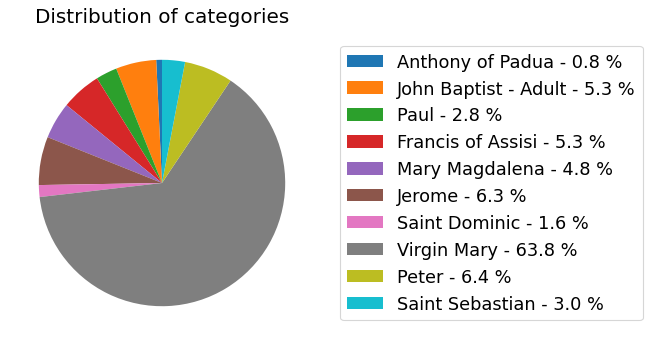
Categories distribution
my_dataset.show_distribution_of_categories()
Properties distribution
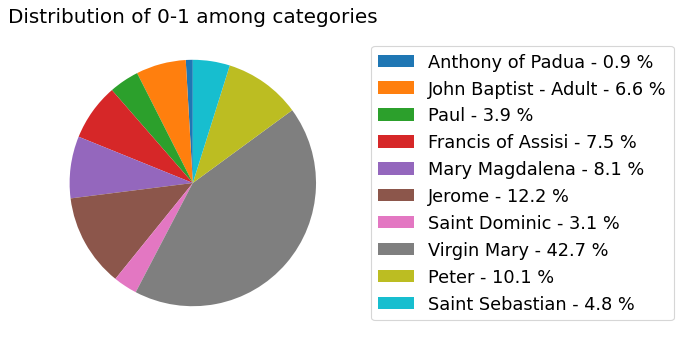
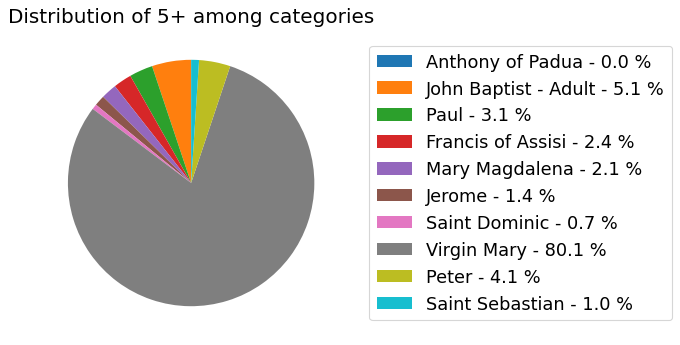
my_dataset.show_distribution_of_properties()
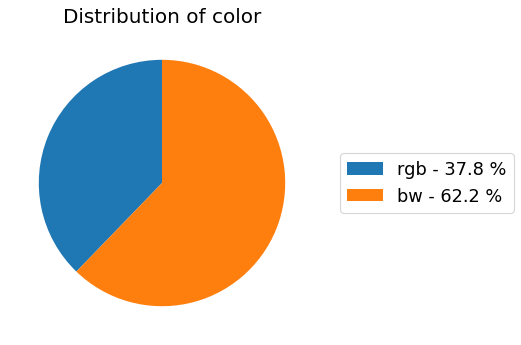
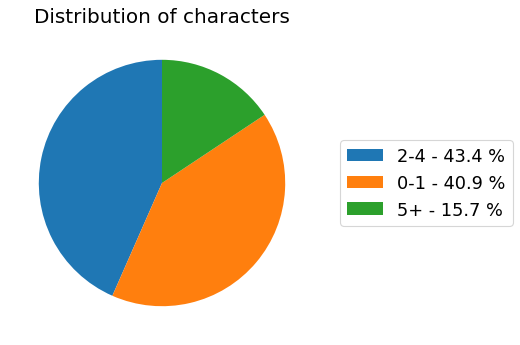
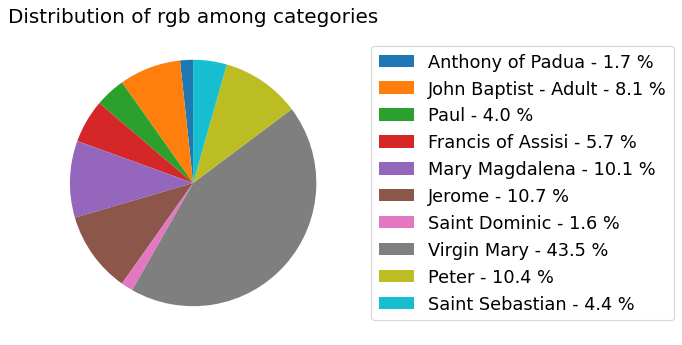
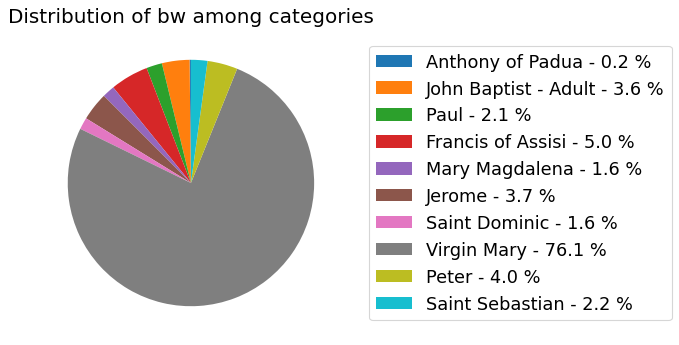
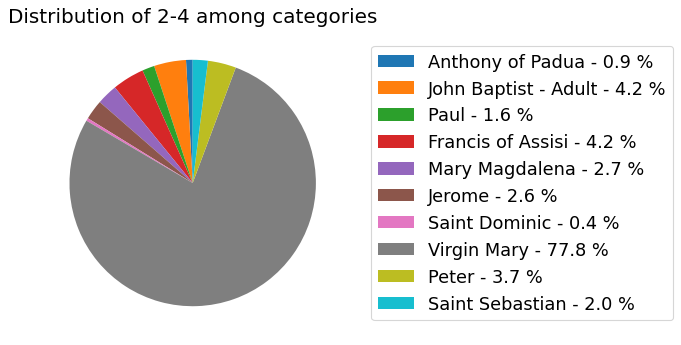
Analyzer
my_analyzer = AnalyzerClassification('my_model',
my_dataset,
metric=Metrics.F1_SCORE,
save_graphs_as_png=False)
Properties analysis
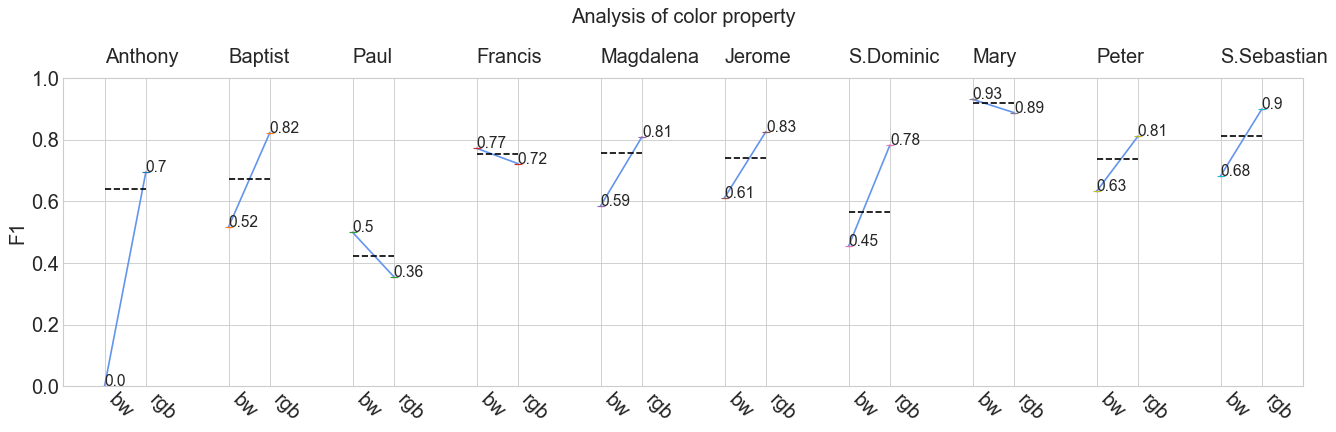
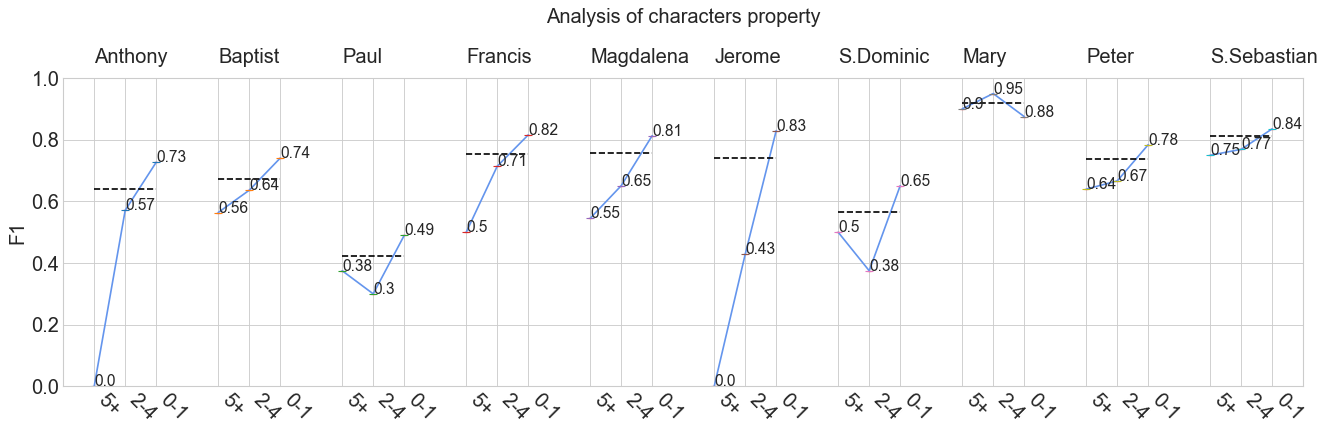
my_analyzer.analyze_properties()
Sensitivity and impact analysis
my_analyzer.analyze_sensitivity_impact_of_properties()
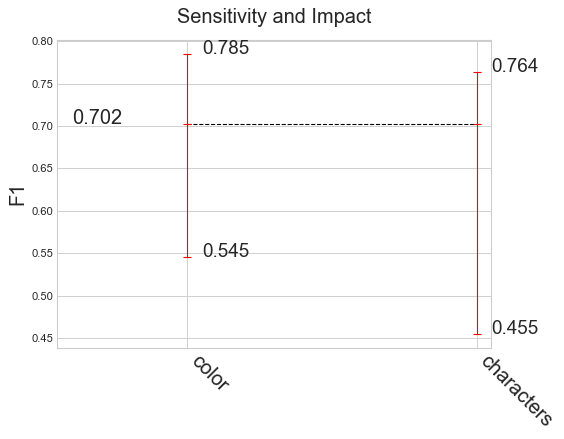
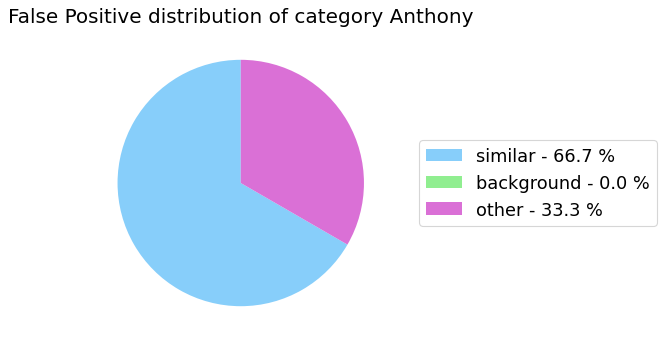
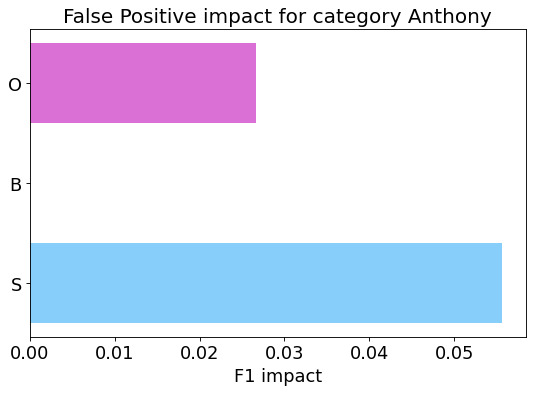
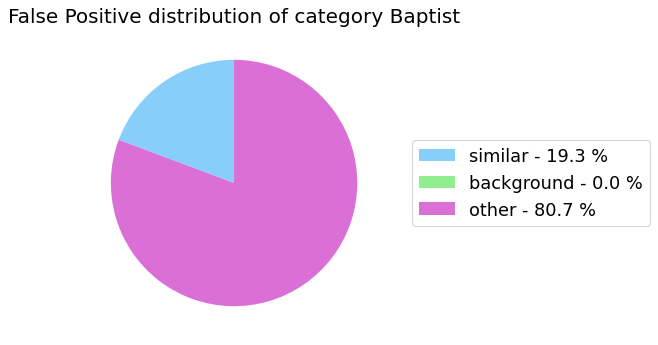
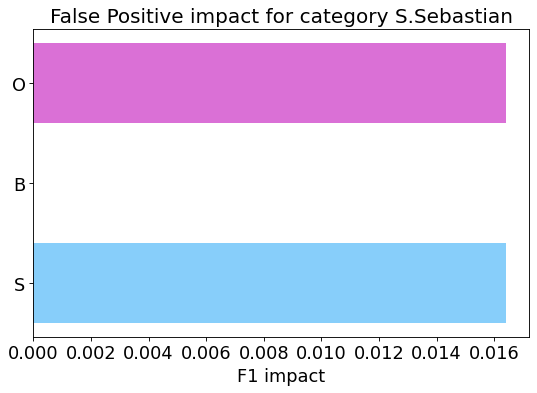
False Positive categorization and impact
my_analyzer.analyze_false_positive_errors()
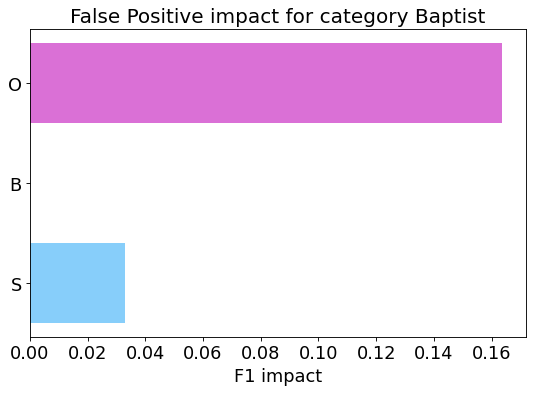
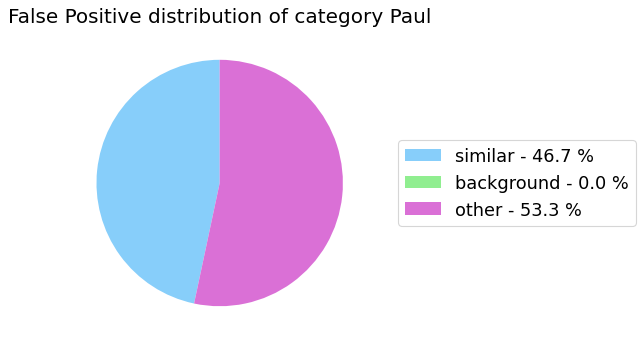
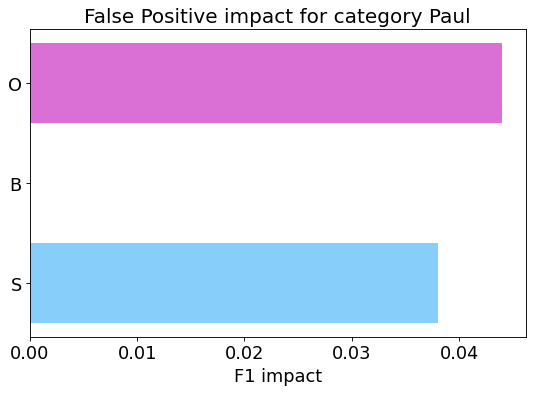
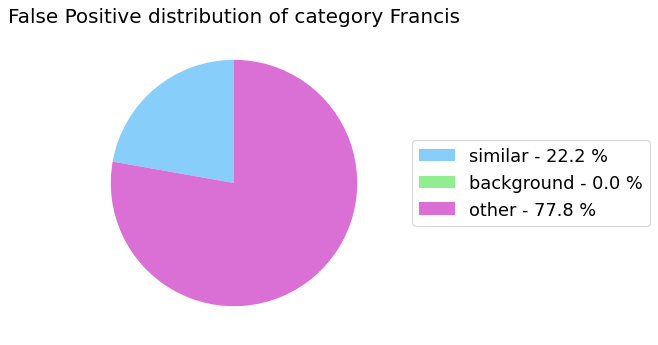
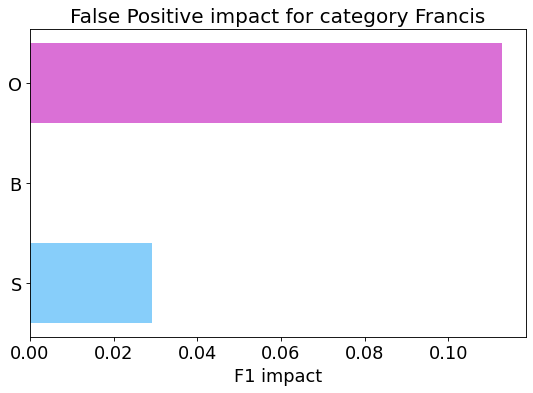
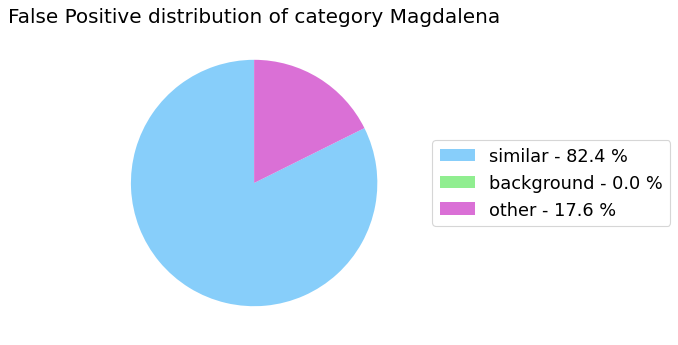
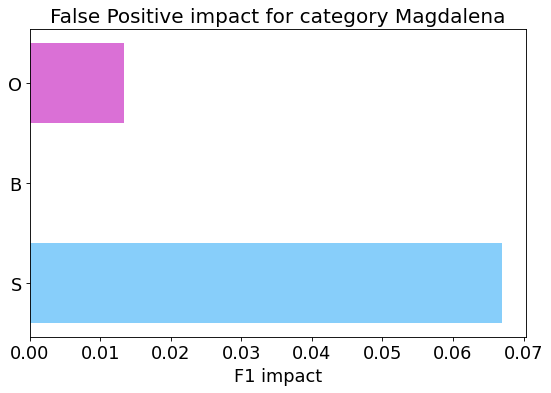
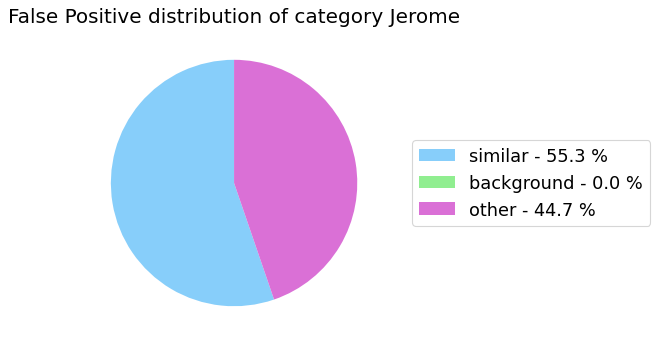
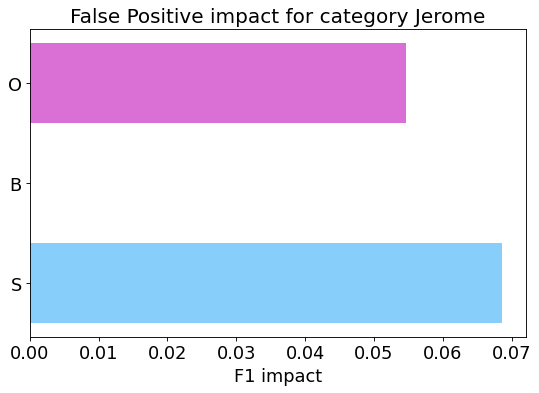
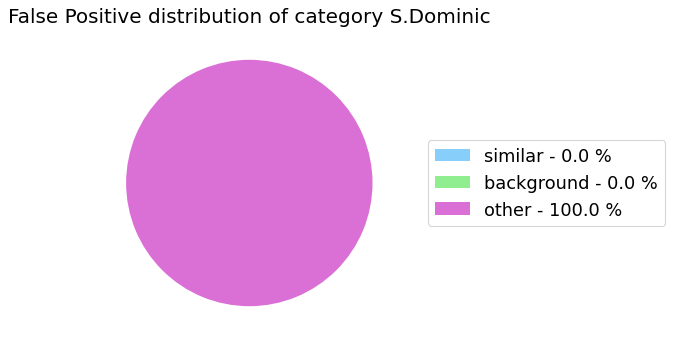
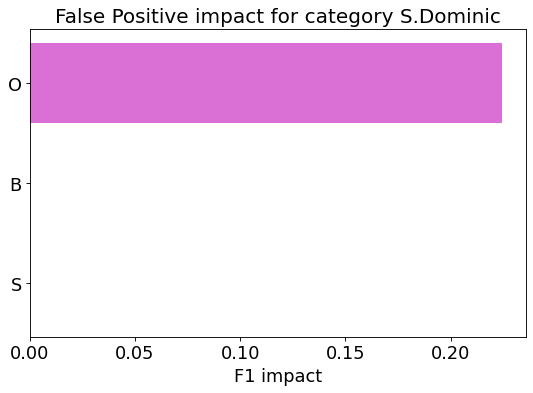
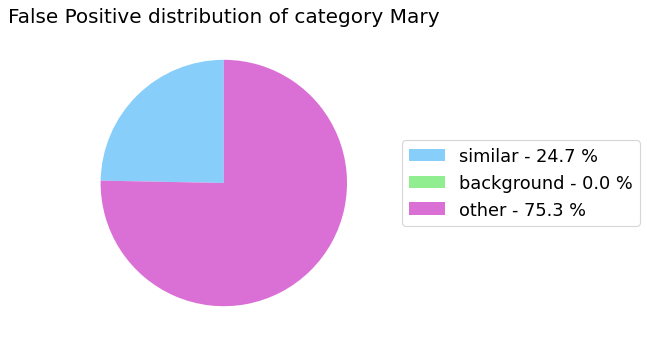
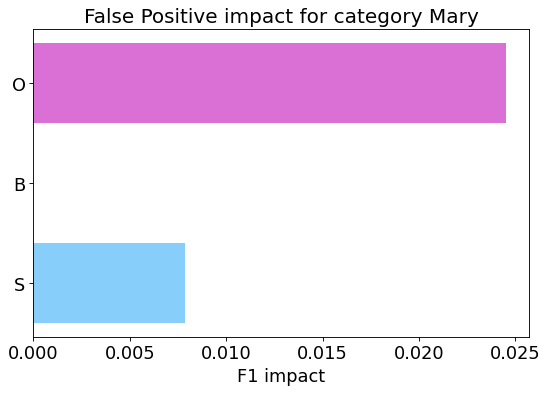
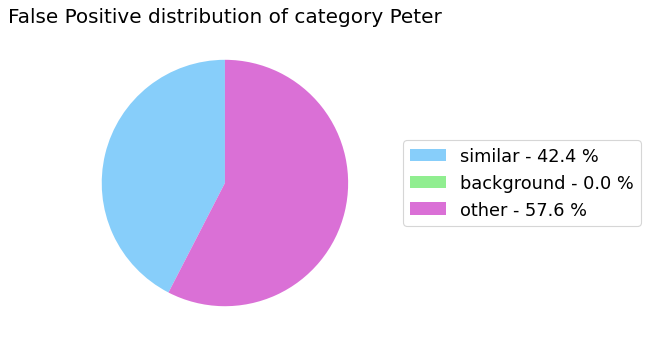
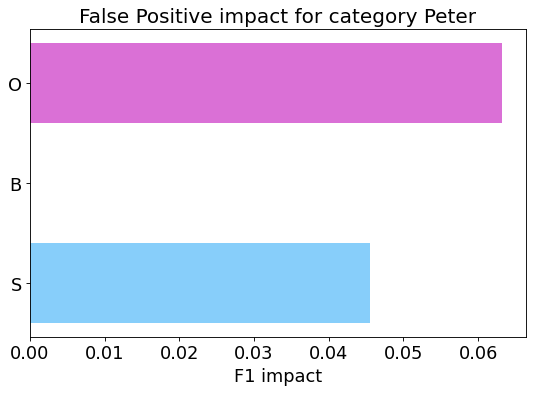
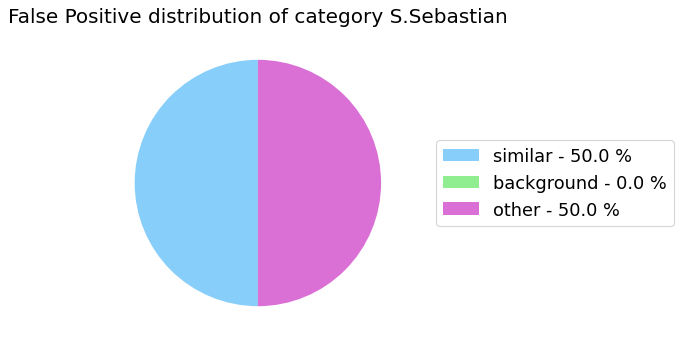
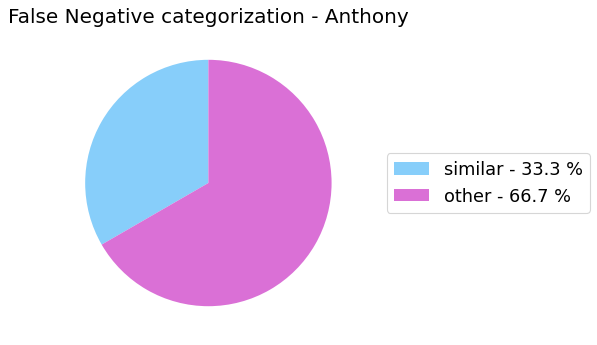
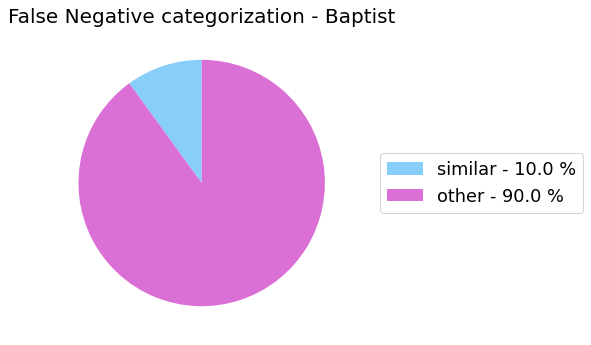
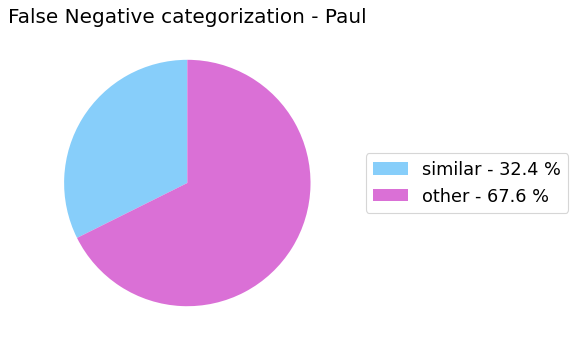
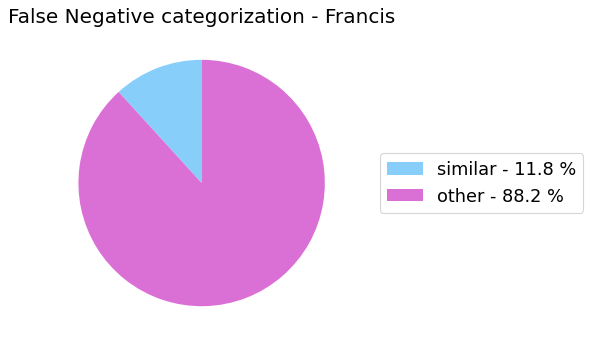
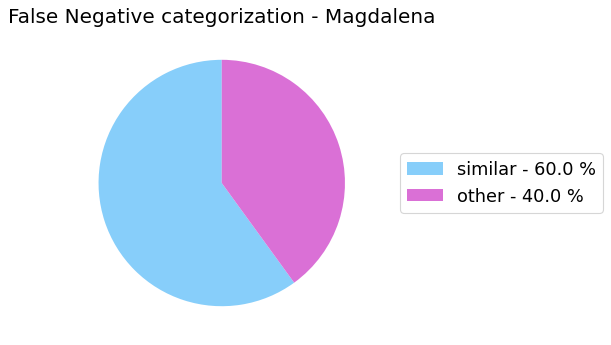
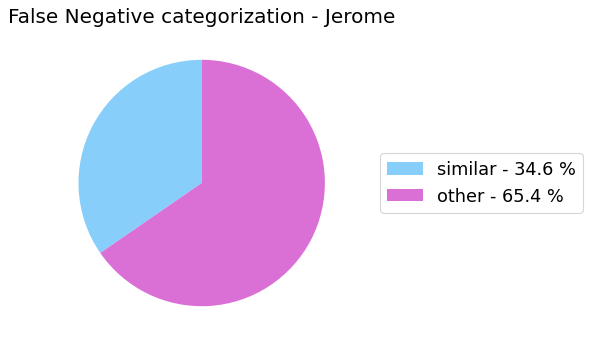
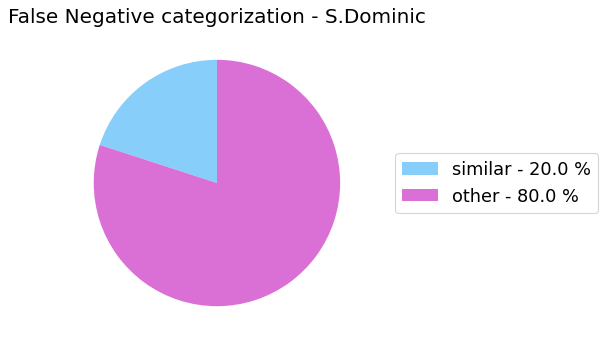
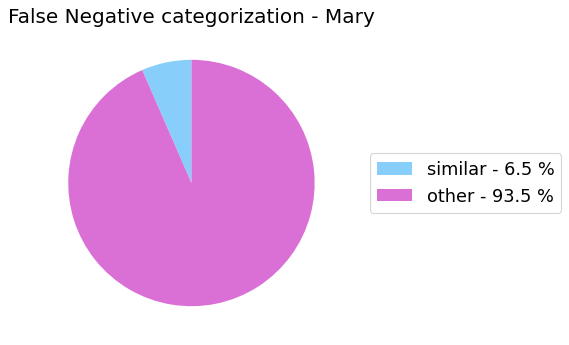
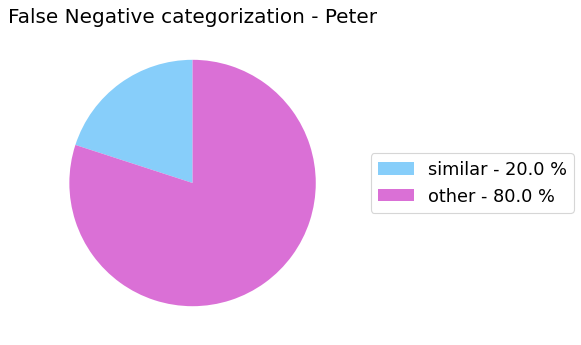
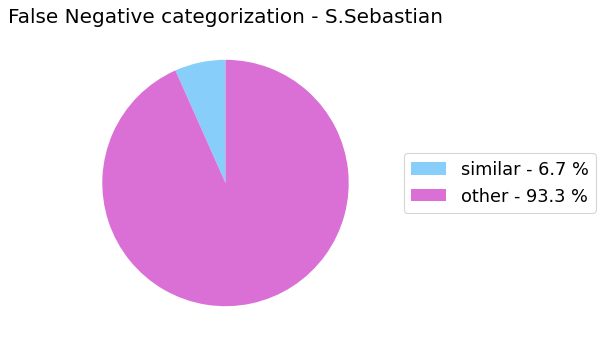
False Negative categorization
my_analyzer.analyze_false_negative_errors()
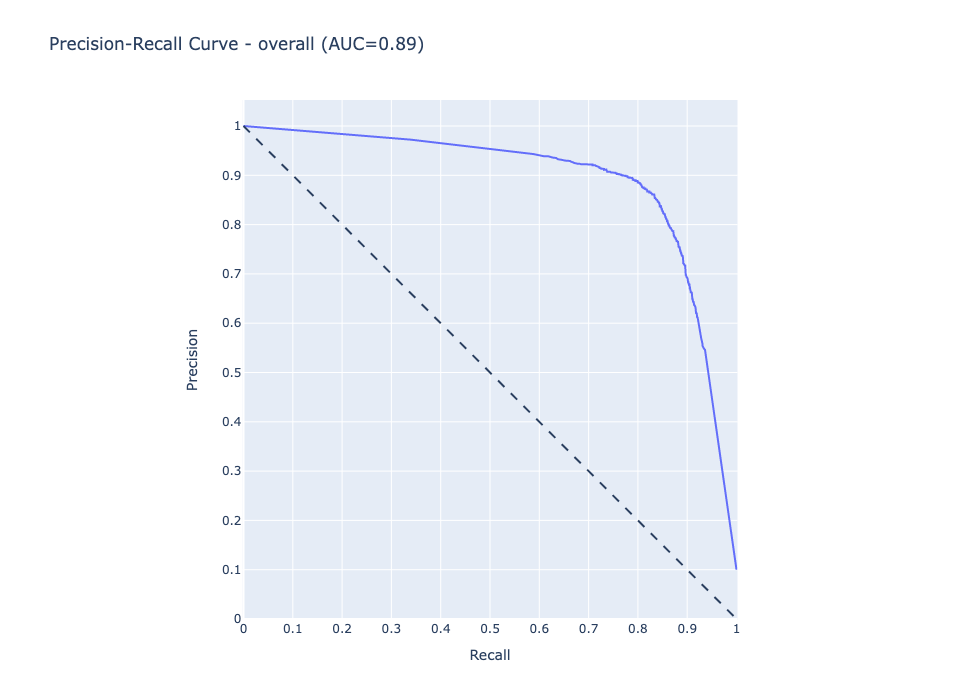
Precision-Recall curve - Overall
my_analyzer.analyze_curve(average="micro")
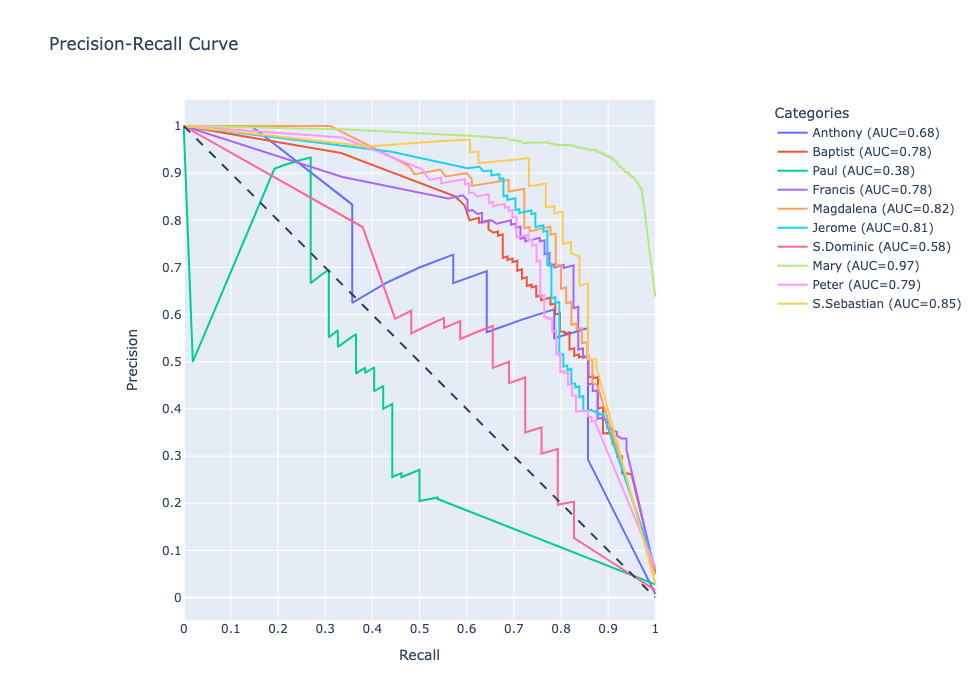
Precision-Recall curve - Per-category
my_analyzer.analyze_curve_for_categories()
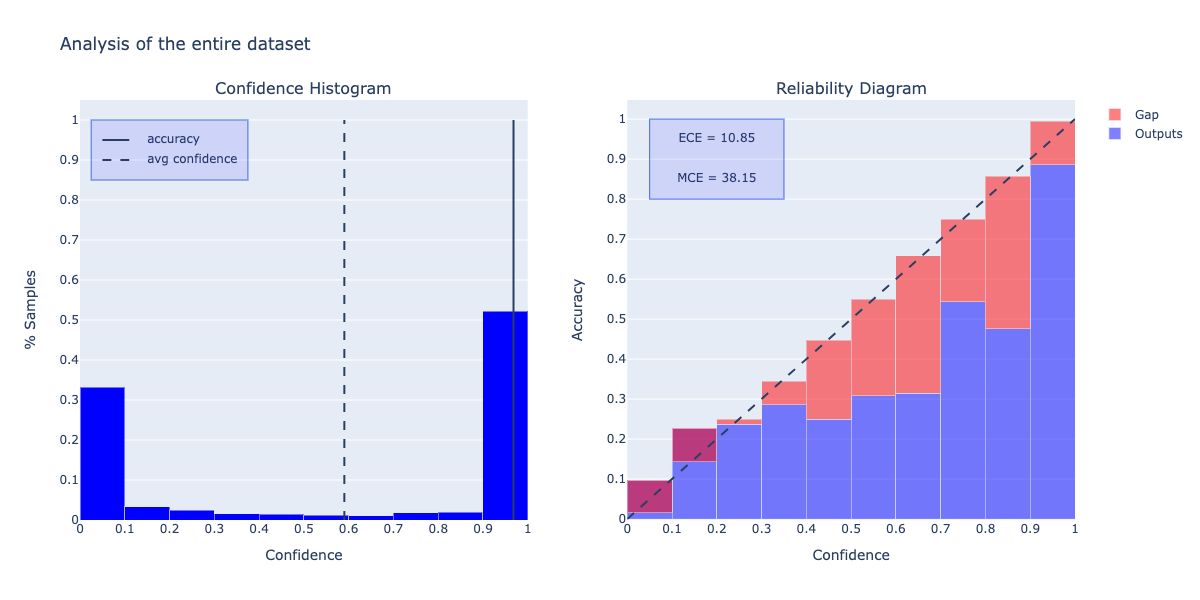
Reliability analysis
my_analyzer.analyze_reliability()
Performance summary
my_analyzer.base_report()